One of the most fundamental elements of the Intercom platform is how it handles user data – for us and our customers, the ability to access, track and filter data about users is what makes Intercom such a powerful solution.
Some important functionality hinges on matching user data against certain criteria – it’s what allows us to send auto-messages to specific users, for example. That means the process of updating the user state is extremely important, and a single user can be updated thousands of times per day. We primarily use DynamoDB to store the latest user state.
However, we realized that our Customer Support team needed more insight into the historical state of a user at a specific point in time, particularly when they needed to troubleshoot problems or verify why a specific user matched certain message criteria at a previous time.
“We wanted to allow our customer support team to self serve when digging into the historical user states”
This was not easy to do given the volume of user data. It required our engineers to dig into logs and combine all the relevant information of what happened to a user object at any given moment in time. Grepping logs is not scalable and involves a lot of manual work, which is prone to mistakes.
We thought there was probably a better way to automate a lot of the investigative work that was involved here by more efficiently surfacing historical changes in user states. We wanted to allow our customer support team to self serve when digging into the historical user states.
Leveraging existing technologies
In exploring ways to better help our customer support team, we had two main requirements:
- Allow access to historical user state changes, reliably and quickly
- Display this information in an easy-to-comprehend way
The self service tool needed to be optimized for writes. Users are updated frequently, but the need to troubleshoot them is infrequent. Historical user states would need to be retrieved a maximum of a few times per day, but often with days of no activity at all.
To support that, we wanted to be able to get the real-time updates of a user. DynamoDB Streams is a service that allows you to capture this table activity. Each update for a user is captured in a DynamoDB Stream event. It was a natural solution that we could leverage to develop our internal tool, called the user history tool, or UHT for short.
Building our user history tool
When we receive a DynamoDB Stream event for a table activity, we store the update that happened to the user. We needed to persist these real-time updates without having to store all the intermediate states of the user objects because with so many updates to user states, a database table would grow too fast. In response to each event, a lambda function is triggered, where we do the processing. This operation has two main responsibilities:
- Calculate the diff between the old user state and new user state in the Stream
- Store the calculated diff in a dedicated user history DynamoDB table
Since the records in a DynamoDB stream are in a JSON format, we obtain the diff of two JSON objects. The diff produced is in a JSON Patch format. The patch looks like:
[
{ "op": "replace", "path": "/baz", "value": "boo" },
{ "op": "add", "path": "/hello", "value": ["world"] }
{ "op": "delete", "path": "/foo"}
]
Together with the calculated diff, we store the user_id and sequential time to live (TTL) value. Setting TTL on a record enables us to reduce the amount of data stored. It also allows us to clean up records older than 30 days for security purposes. TTL functionality is provided by DynamoDB at no extra cost.
On the admin side, once an admin requests user history several things happen:
- Current user state is read from the main user storage.
- Stored diffs for the user are loaded from the user history table, paginated by 30 states at a time.
- Starting with the current user state, a list of previous user states is generated by applying a JSON diff patch to each previous state.
- By comparing two adjacent states, we generate an HTML representation of the user changes. Generated HTML looks a lot like Github PR changes, with old values being highlighted in red, while new values being highlighted in green, so that the changes are immediately obvious.
This is what the end-to-end architecture looks like:
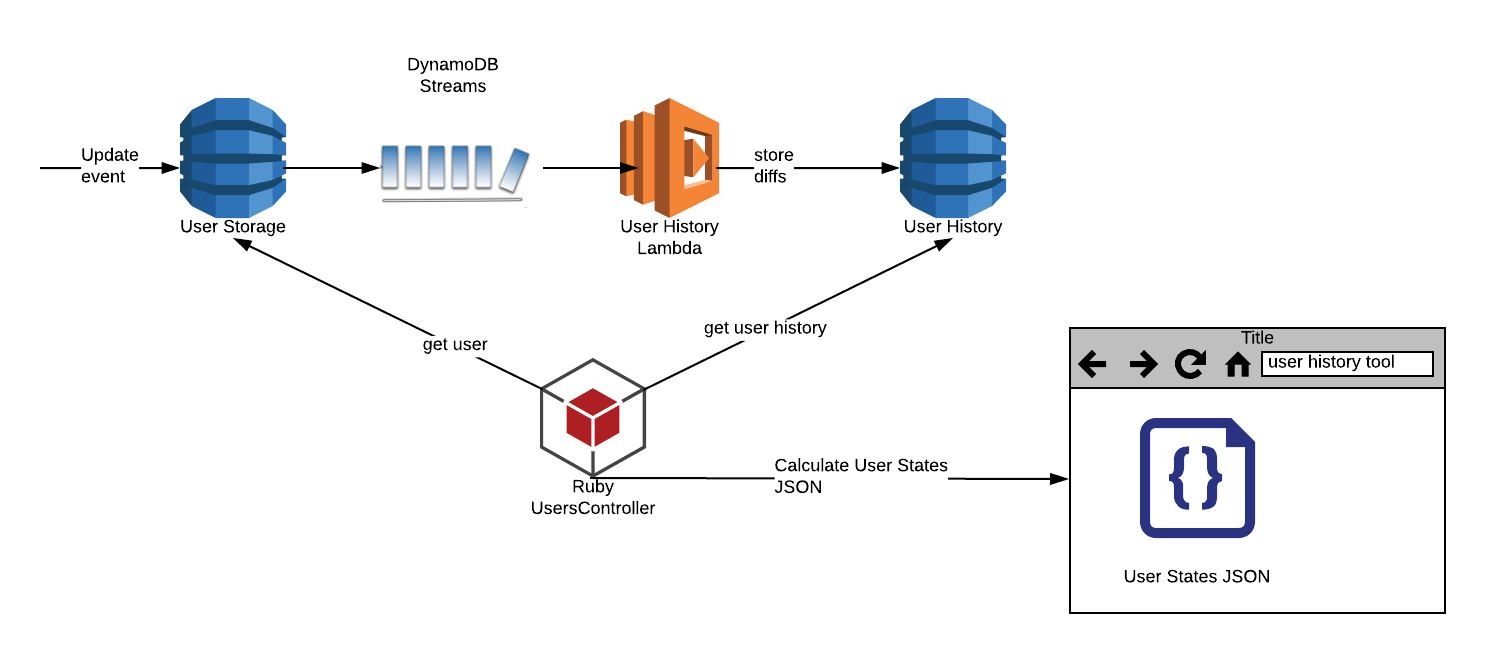
The flow of processing and storing the diff patches is serverless. AWS Lamdba takes care of everything required to run and scale code with high availability.
Automating repetitive tasks
DynamoDB Streams were built to capture table activity, and their integrated AWS Lambda triggers easily enabled us to visualize updates in objects.
“Thinking simple and leveraging common technologies is part of our engineering philosophy”
The UHT is now used internally by our Customer Support team and decreases the time spent on investigating problems related to the historical user states. Automating this manual repetitive task allows us to be more productive when solving our customers’ issues and eliminates the risk of making mistakes in the process.
Thinking simple and leveraging common technologies that we know and use frequently is part of our run less software philosophy. We put it in practice by picking the right, reliable technology to enable us to build a simple, elegant, serverless solution which served our needs well.