
Hope for the best or prepare for the worst? How we manage critical incidents at Intercom


Main illustration: Skip Hursh
Almost every software company today has some kind of incident response process to help them navigate major service outages. Intercom is no different, and up until mid-2018, our incident response process had worked successfully.
We had many experienced engineers who had been part of on call rotations at other companies, we ran basic postmortem exercises and overall our frequency and duration of outages was pretty good for a company of our size.
However, after a particularly complicated and long-running incident (known internally as “The SpamHaus event”) we realized that we needed to significantly up our game. As our business has grown, so too has the potential customer impact of any incident. Our engineering organization has also grown, and there are now significantly more stakeholders who needed to know what was going during an outage. Our incident response processes for smaller events was solid, but for particularly critical issues, it was clear there were many opportunities for improvements.
Over the past few months, we’ve been working on solidifying our incident response process and documentation. We’re sharing it now in the hopes that it will help others adopt a better incident management process quickly and painlessly.
Defining the different stages of an incident
To establish a successful incident response process, the first thing to do is to take a step back and look at what happens in most incidents as they unfold. Of course, incidents come in all different shapes and sizes. For example, a relatively common type of incident might be a brief outage of Intercom due to a database failover.
However, based on our experiences in mid-2018, we were particularly interested in solving for the more serious outages that would require a more formal incident management process. These are situations where there is no clear fix to the problem, the duration of the problem is prolonged, or the customer impact is grave.
The first step was to define the different stages of an incident:
- Identification: The outage is identified, usually by an on call engineer, and a priority is assigned, which can later change as we understand the full impact.
- Triage: An incident response team will investigate, following procedures that can change as the event evolves. This is usually managed by an experienced engineering leader.
- Communication: When needed, communication with customers, support, sales and leadership can occur. This can be done by the Customer Support team or through informal channels.
- Resolution: The incident is resolved, and follow-up actions like an incident review occur. This was managed by engineers with some oversight from engineering leadership.
We also worked to clearly classify the severity of incidents. For example, some of our team had an incorrect assumption that a P0 was always security related, so we invested in education on this in addition to providing more examples of what we classify as P0 (a large event that puts the public reputation of the company at risk) through to a P3 (a minor defect or bug that should be fixed). We further offered guidelines on how something is escalated from a P1 to a P0 (such as extended incident duration, or catastrophic customer impact such as data loss), which helps in especially complicated situations.
Previously, there had been different people involved at different stages, working off their own mental models of what needed to be done, and with no clear guidance on what to do, especially when things aren’t going to plan. While this can work for smaller companies, for an operationally mature company like Intercom there needs to be some semblance of clarity and accountability as to who is doing what at any given stage.
Which brings us nicely onto our next point…
Defining roles
Incidents can be stress-inducing enough as it is, so the last thing the team needs is uncertainty as to who they need to help out, and who needs to communicate with whom. By defining clear roles in advance, you create an environment which makes easy, clear communication between your teammates all the more simple.
Firstly, we introduced a formalized Incident Commander role. In times gone by, we generally did have somebody managing the event, but this was done informally and without explicit responsibilities. With an Incident Commander, we now have someone who can act as a single source of truth and take responsibility for managing the technical resolution of the incident, end to end. This was not a role that we invented out of thin air. It’s a commonly used role across our industry (and beyond), though with a variety of different titles and responsibilities.
In addition to managing the event itself, the Incident Commander is also accountable for all technical communication that occurs. Unlike other companies, we made a deliberate decision not to spin up a separate “Technical Lead” role as well. Given the scale of our organization, separating the roles of Incident Commander and Technical Lead was not fully justified, though we decided that for a particularly complex event, the Incident Commander has the ability to nominate a Technical Lead.
The second role we created was Business Lead and this was designed to solve for how we communicate with people outside the engineering org. To do this, we created the role of what we refer to as the Business Lead. This is the person responsible for coordinating all communication outside of the incident response room. That means communicating with our customers, our Customer Support team and sometimes all the way up to our leadership team.
We already had a lightweight process for partnering with our Customer Support team (for example, updating Intercom’s status page for lower priority incidents), but when a particularly high severity incident occurs, the Business Lead can help to communicate more frequently and proactively to customers, and ensure the sales, leadership and Customer Support team are aware of the potential business impact.
Defining principles
At Intercom, we generally like to work from first principles whenever possible. Principles are especially relevant during fast-moving events like outages. Even with the best documentation and the most robust processes in place, the reality is that outages are inherently unpredictable events where it is impossible to anticipate every situation you may find yourself in. That’s why it’s important to have a set of guiding principles to help people make autonomous decisions when no explicit steps have been defined.
Here a few examples of our incident management principles we created:
Do one thing at a time
Changing two or more things at the same time is risky and can be harmful. It creates more work to keep track of what’s going on, there’s more things that can go wrong at the same time and you may not be sure exactly what just made things better or worse. Do things sequentially, unless there is very good reason to do otherwise. Verify the impact of each change made before moving on to the next.
Try the easy stuff first
There are common recovery strategies that can work in a variety of situations, sometimes even if you don’t have anything to precisely associate it with what you’re seeing. Rollback the app. Failover a database. Toggle a feature flag. Clear a cache. These actions are common things that happen regularly, are quick and safe to execute. Code or infrastructure changes can be slower to implement and may depend on a healthy build and deploy pipeline. Asking the team “what can we quickly try out?” and ruling things quickly and safely can result in a fast resolution before a precise diagnosis of the problem is made.
Wrap things up quickly
It’s common to let things drag on a bit before closing out an incident. Don’t do this. Remove people from the room and shut things down promptly as soon as it’s clear that things are stable, and you are no longer in a crisis mode. Make sure the owner(s) of follow-up actions know they have work to do and what expectations we have of them. The quicker we get back to normal business, the smaller the impact.
Training and documentation
Documentation is one of the most critical aspects of a solid incident management process. In the tinderbox environment of a major incident, the last thing you want is people sitting down to a blank page or reinventing the wheel and creating new processes from scratch. During critical incidents, every second counts and documentation will give your team an all important headstart to ensure you recover as quickly and seamlessly as possible.
The documentation we’re most proud of is a fun training video we created for people who are interested in being an Incident Commander. We trained four commanders in both our Dublin and San Francisco offices and set up a PagerDuty rotation that aligns with our office hours, since that’s when most of our incidents occur. But we also wanted to democratize the process and make sure everyone had access to our incident management tools and resources.
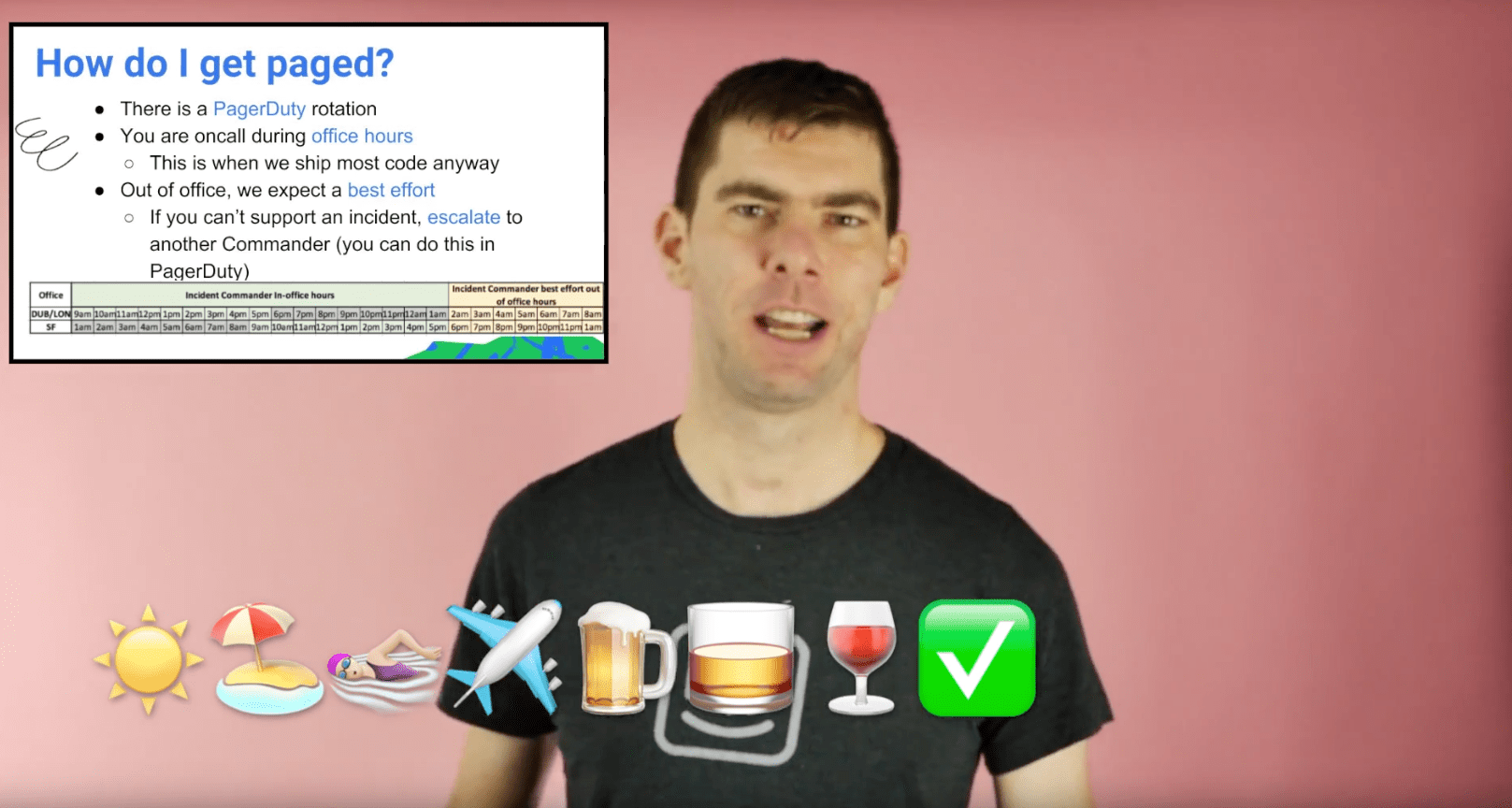
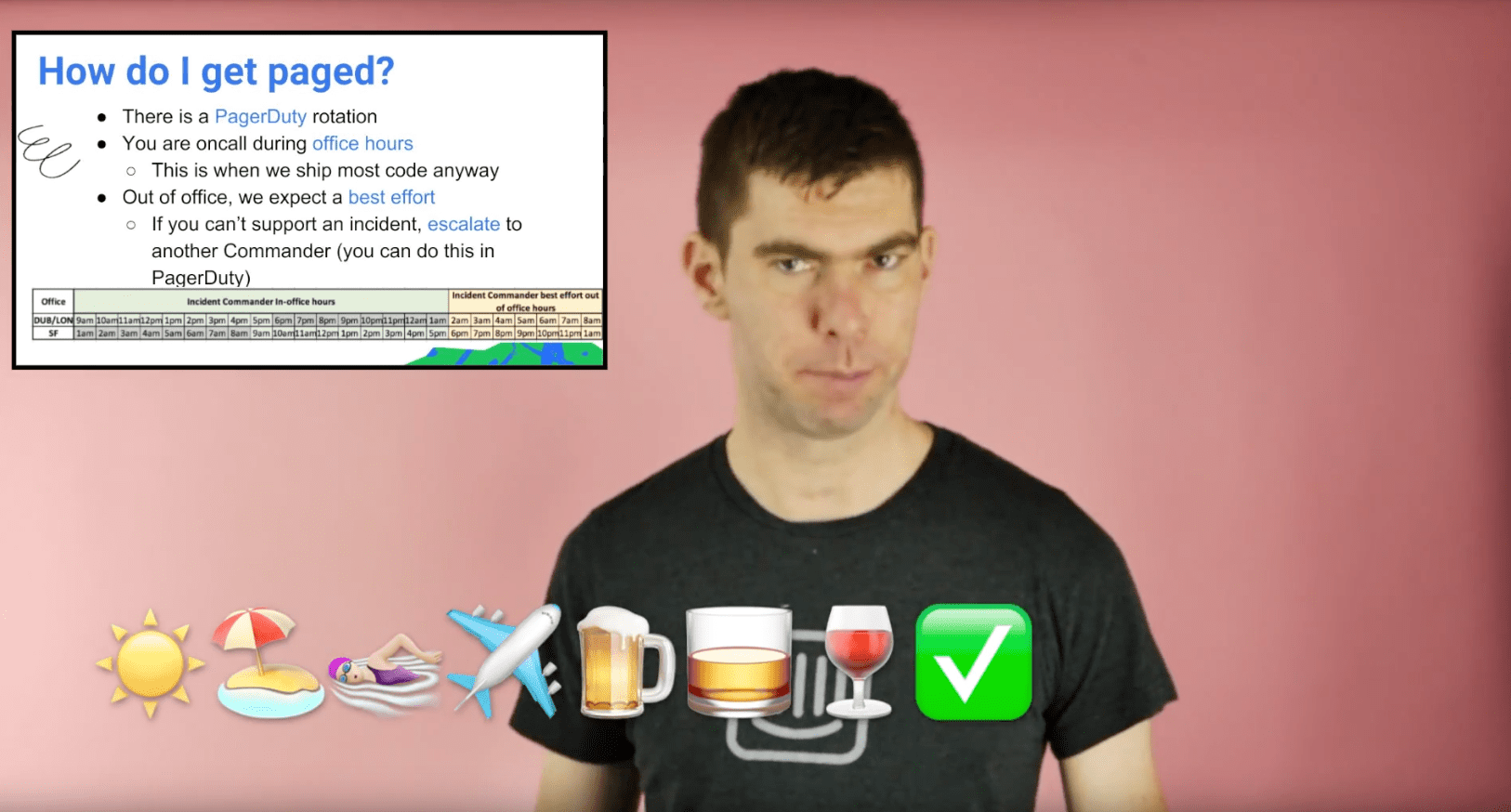 We also wrote plenty of traditional documentation, such as incident checklists and onboarding guides.
We also wrote plenty of traditional documentation, such as incident checklists and onboarding guides.

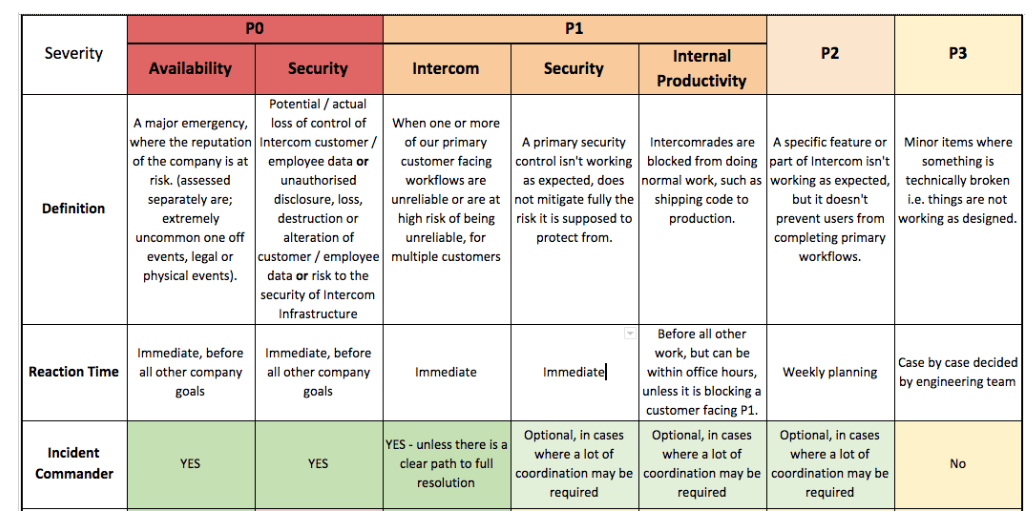
Excerpts from our documentation for Incident Commanders
As a result of this work, we’re in a much better position. When something goes wrong, we have the right people available online restoring service to our customers. And when we need to tell our customers or internal stakeholders about what’s going on, we’re doing so far more effectively.
Putting it into practice
In the same way you wouldn’t ship a new product without having run it through a beta, it was important for us to test our incident management process in action before rolling it more widely throughout the company.
One of our most worthwhile exercises was to get people to brainstorm potential scenarios that could hurt Intercom and our customers in a variety of ways, and then use those scenarios to pressure test our new processes to see if they were up to scratch. This was, quite frankly, a bit terrifying, but it was a really useful exercise for us in both raising awareness with leadership teams and reassuring us that our processes would work.
We were also soon given a real-life incident to put our processes to the test, during a major outage of our search infrastructure. The event was complex and required multiple streams of work to resolve. Our principles-based approach to the event gave a shared understanding of how to operate and meant that the Incident Commander during the event was confident in splitting up the response team into multiple groups to take on different work to set us on the road to recovery. Our customer communication was accurate and timely, as was our internal communications. Had this happened three years ago, I’m not sure we would have been equipped to handle the situation as successfully.
We know our new incident management processes are just the first step in a long journey ahead. As Intercom continues to scale, we’ll have to continue to invest in how we respond to bigger and even more serious incidents. However, we feel like we’ve put the right foundations in place to be able to able to respond to major incidents without chaos and stress, and with a proactive communication style that keeps our customers, and our stakeholders, aligned.







